🤖I built a tool to scan websites for AI readiness. spoiler alert: we're not ready
AI agents are recommending products to your customers. Is your site ready?
Welcome back, today's subject: the agentic web
AI is getting a sort of maturity to it now, agents are browsing the internet, looking for content, products, and data on behalf of their users.
Sometimes they'll recommend products or services to their users, sometimes they're able to action purchases directly.
In 2026, agents are well on their way to becoming a meaningful sales channel. We may not want to admit it but there's a growing percentage of people who are frankly uninterested in searching very hard to find the things they want to know or buy; and there's companies emerging rapidly that are building platforms based on AI product recommendations that suit their users needs.
I'm not advocating for or against that use of the technology, but one thing is clear to me:
Most websites in 2026 don't make it easy to sell to an AI agent
Website operators view agents as either daemons roaming the internet to scrape their precious data and want to block them, or are completely unaware and unconcerned with agents on the internet.
Some companies are now offering SEO services tailored to making your content more discoverable by LLMs, the future of ecommerce and discovery may well rely on how friendly you are to agents providing services to people looking to buy.
But let me ask you this: what's your website missing right now that would make it easy for an AI to browse it?
For the majority of the people reading this, the answer is "I'm not sure"
That's why I built CrawlMark - a benchmark tool for the modern web crawler
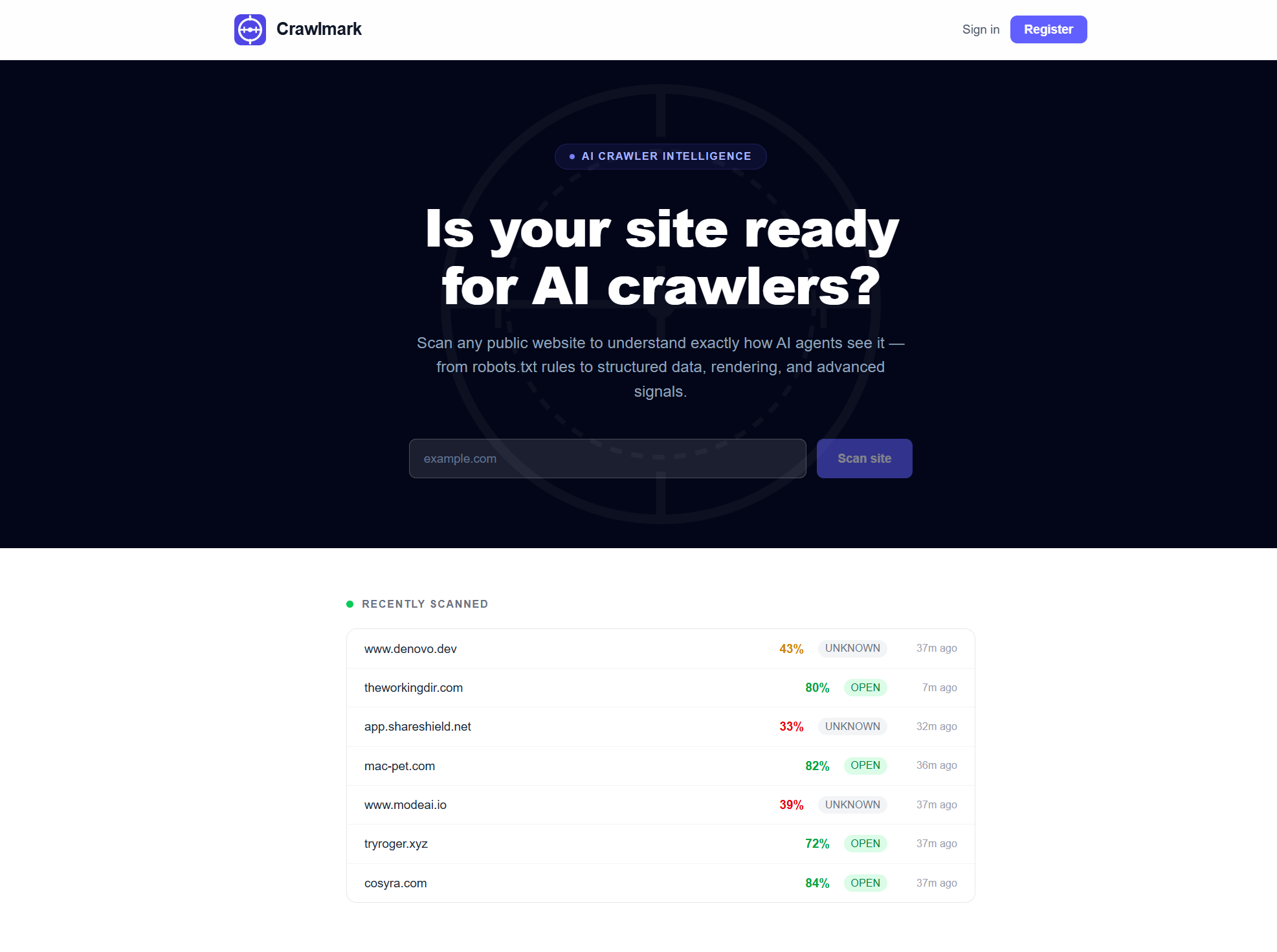
This isn't a site for agents (yet), but for developers, business owners, marketing analysts, etc.
The real people in charge of the needs and requirements of their website.
Just plug in your site url, hit the scan button, and the report will be generated almost right away
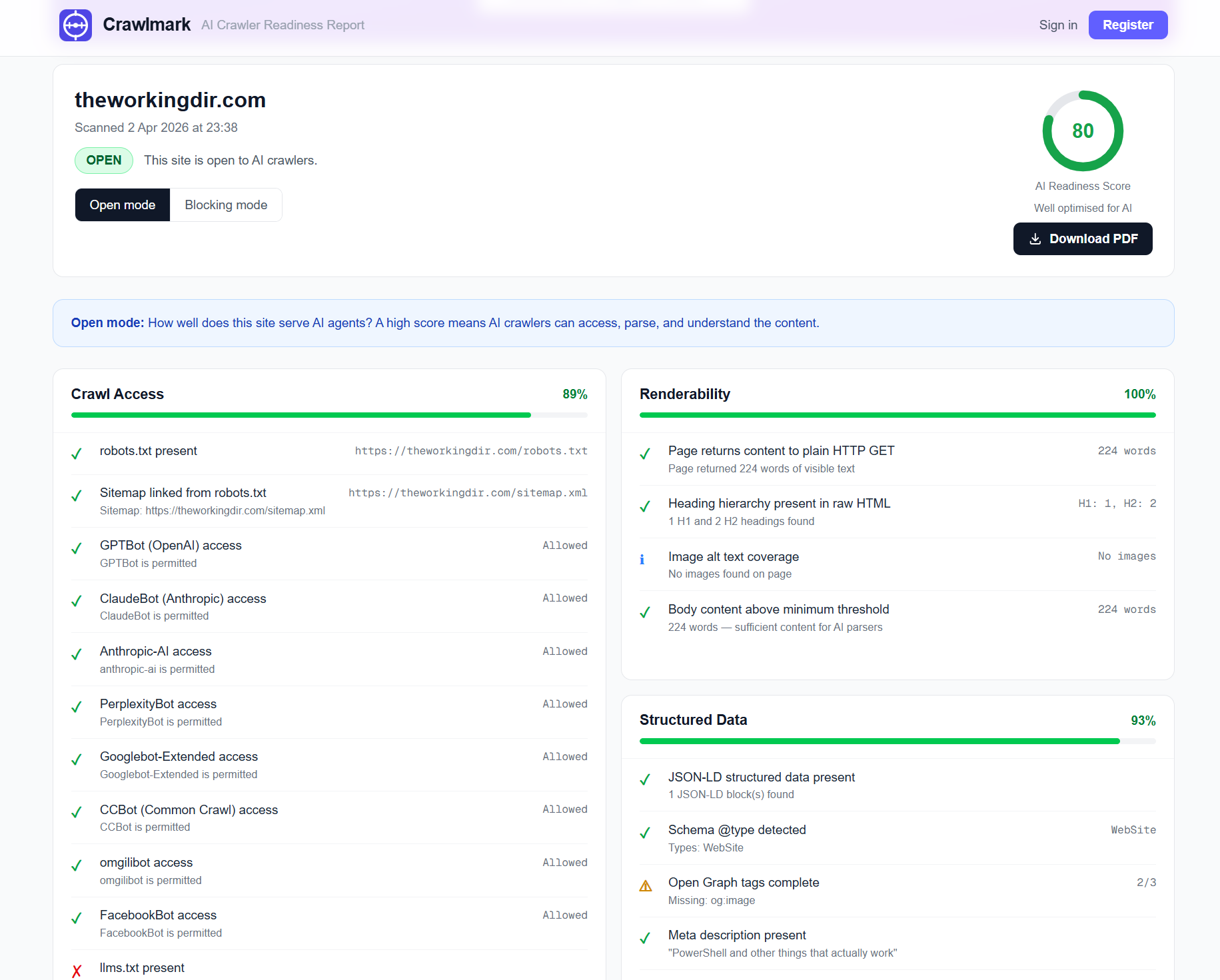
You can share this report, export it as a PDF (registering a free account removes the watermarks for a cleaner look if you're sending this to a client or stakeholder) or just bookmark it for later.
Crawlmark checks for things like robots.txt, llms.txt, sitemaps, how the page renders, whether or not there's structured data, and checks for well known AI plugin, endpoint, and MCP server manifests.
All useful insights in a quick snapshot.
Here's the other thing: these aren't theoretical improvements. You can demonstrate the return of implementing the recommended changes.
What better example to use than ShareShield, a service I operate to send one-time secrets and passwords to colleagues, that self-delete after being opened.
I asked Perplexity, ChatGPT, and Claude about the pricing plans on ShareShield, and the result from all of them was "I don't know"
The reason for this is that the pricing page on ShareShield isn't using the default WooCommerce storefront, it was a table with links to the product pages, and the LLMs couldn't understand that.
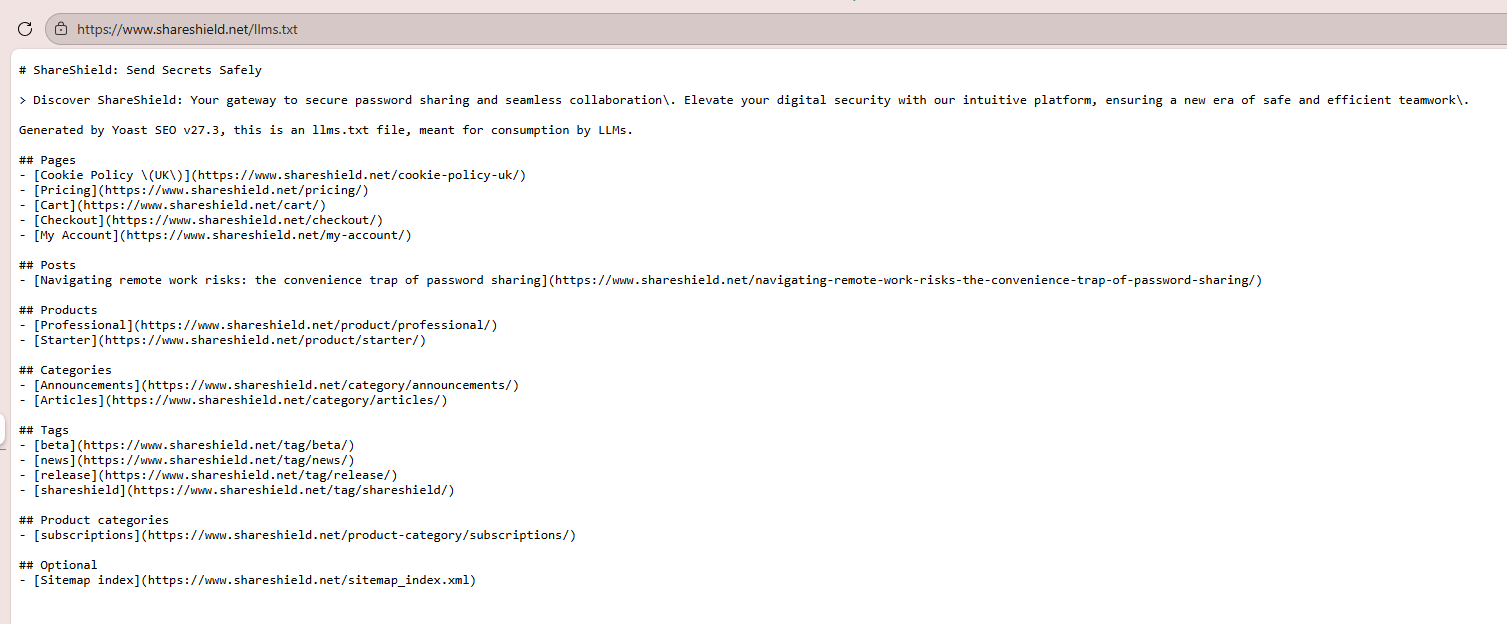
Once I added the llms.txt file shown above, suddenly any agent was able to find & retrieve pricing info just like that.
I had transformed my LLM search appearance in just a few minutes!
But that's my own site, there's only a few products on there, how does it handle higher traffic, higher SKU ecommerce sites?
Real life experiment: Networking supply stores
For my next test I asked Perplexity where I could buy Unifi switches in the UK, it came back with this:

So a few vendors, including Unifi themselves. I've used Broadbandbuyer in the past so I was immediately interested in how they stacked up.
My next question was what deals were on? To see how they compared with pulling price data into an LLM
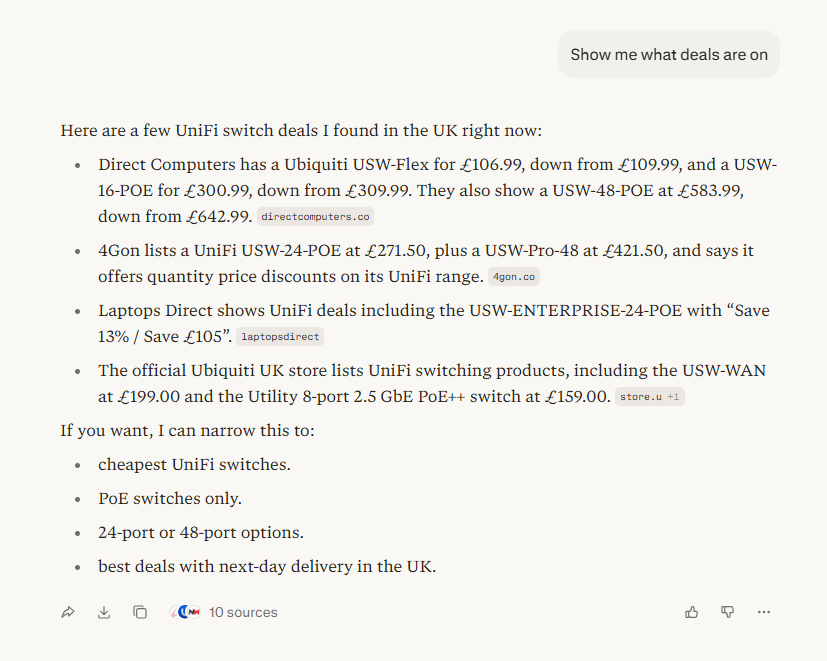
The results look fine don't they? But hang on - Direct Computers doesn't have a USW-Flex for £106.99 right now, is that a cached result? And it looks like Broadbandbuyer's vanished from the list entirely.
Lets break out Crawlmark and see how they score.
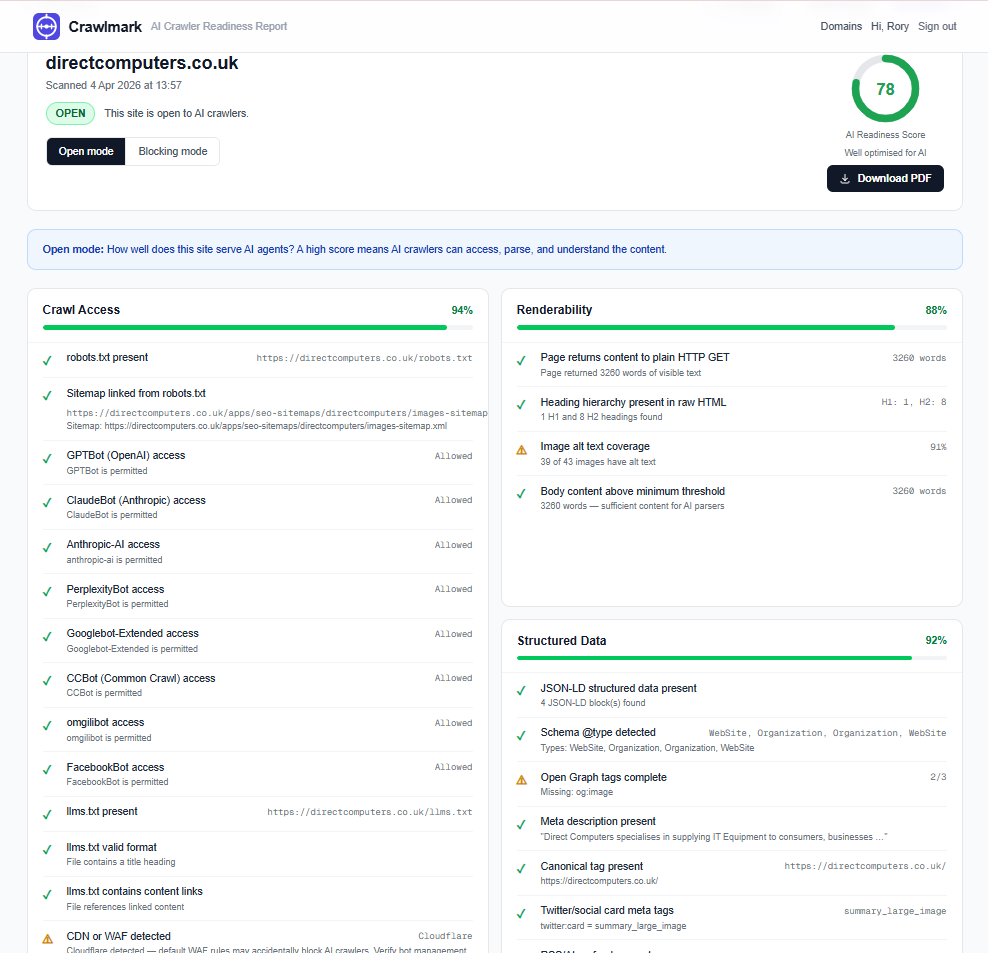
Direct Computers scores very well - they even have an llms.txt file! Lets check them out with Claude to see if that gets the right info:
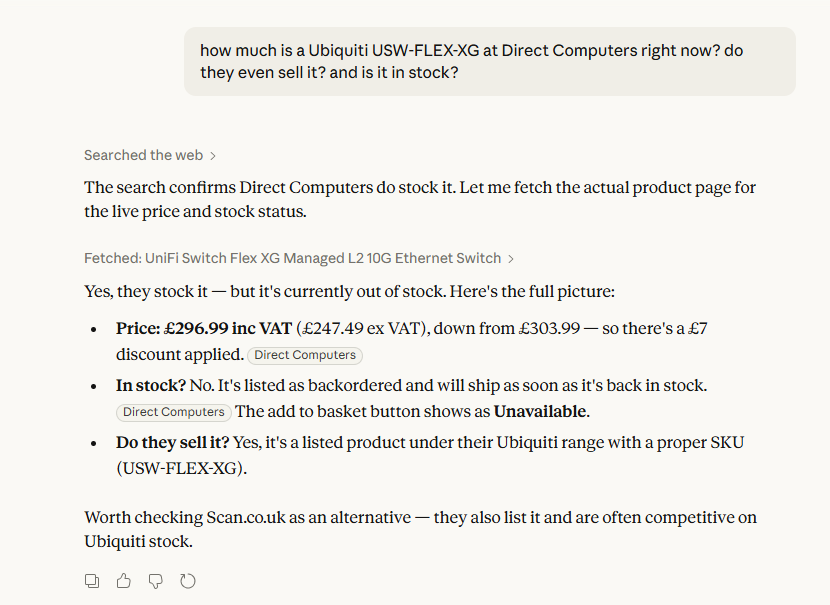
So close! the price is perfect, it acknowledges their current offer on the switch, and confirms they sell it. The only thing wrong is the stock status. I pulled the json schema from the listing on the site directly to check out what they're exposing:
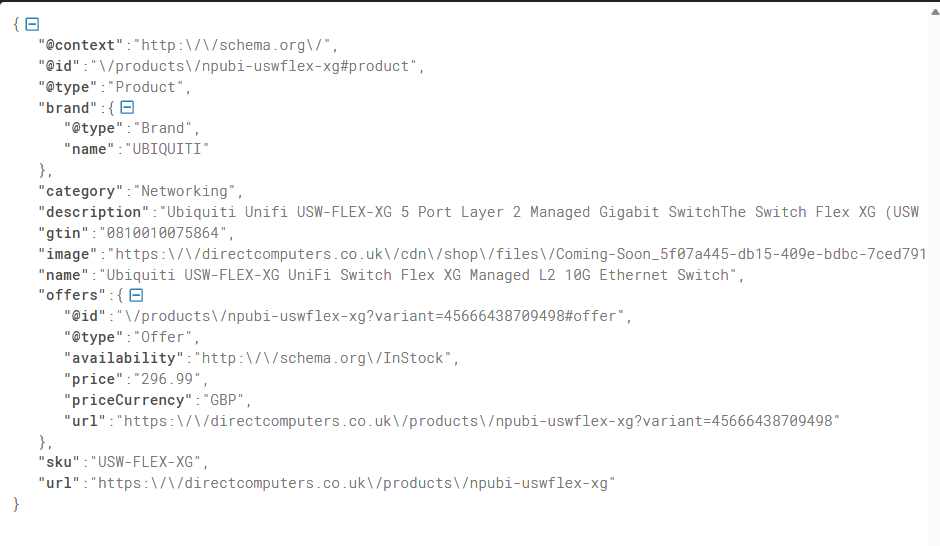
All the info is there, being presented properly, very close but that kind of slip could make Claude omit the result from a more general query, as mine was highly specific.
Why did perplexity fail to fetch the right details but Claude did?
My working theory right now is the llms.txt file I praised them for earlier. I checked it out and it's over 90K lines long, that's nearly 40MB! So my best guess right now is that Claude's larger context window saved the day and made the search result more accurate.
Lets check out broadbandbuyer, since they didn't even surface for specific pricing questions.
I asked Claude to check for the same product, it failed to fetch in the backend, then gave me a cached result:
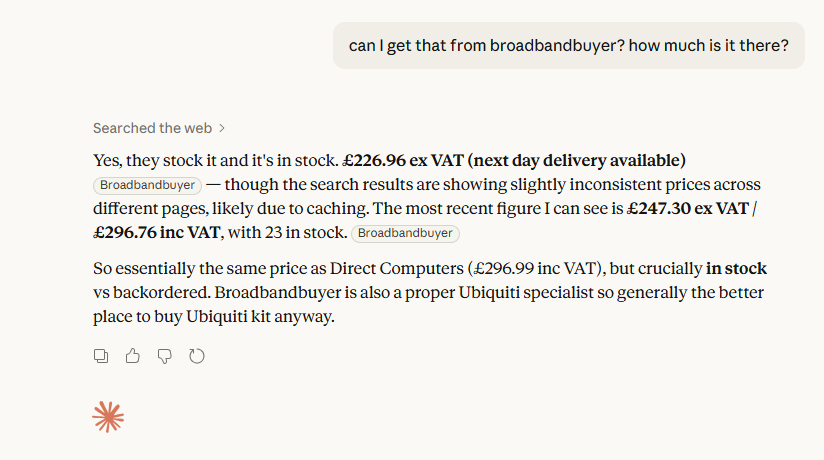
So that's starting to explain things, it can't fetch from the site. Let me check it in Crawlmark
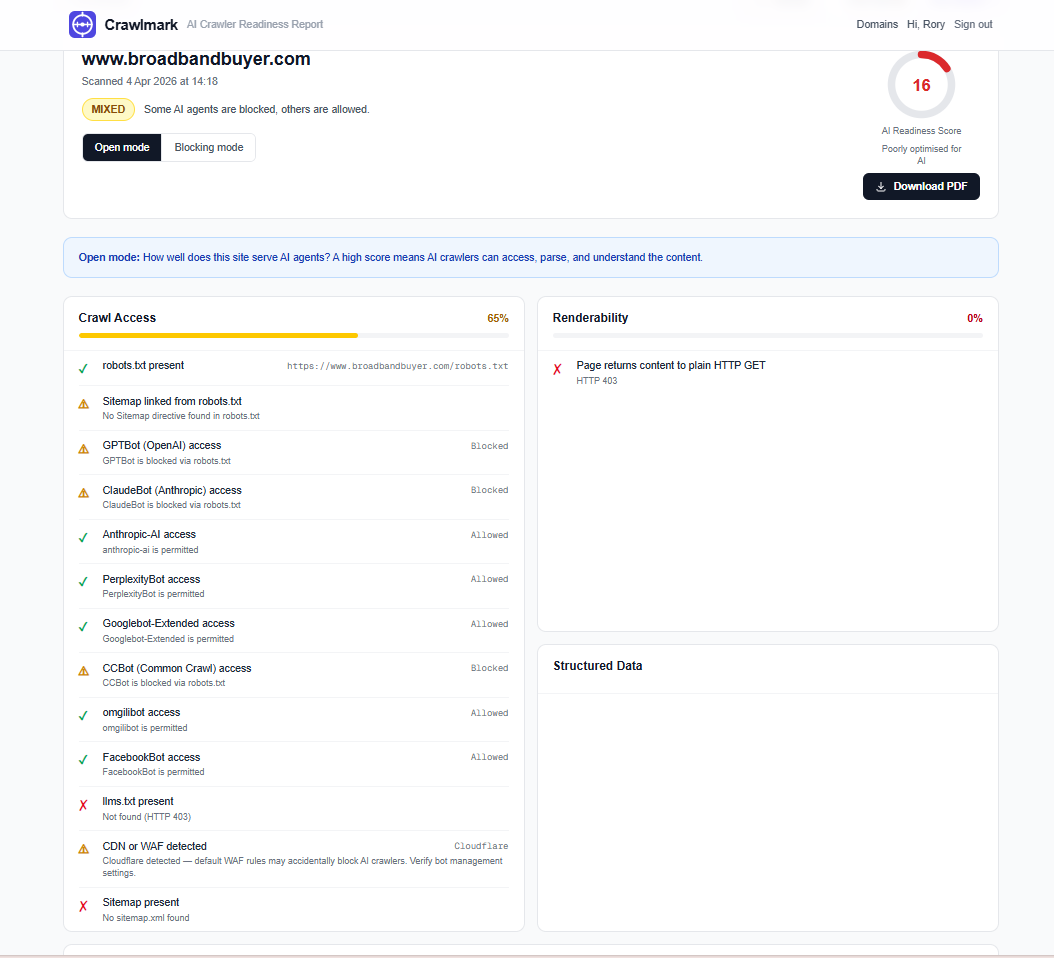
And there it is, an awful result from them. If I go straight to the site I can see why
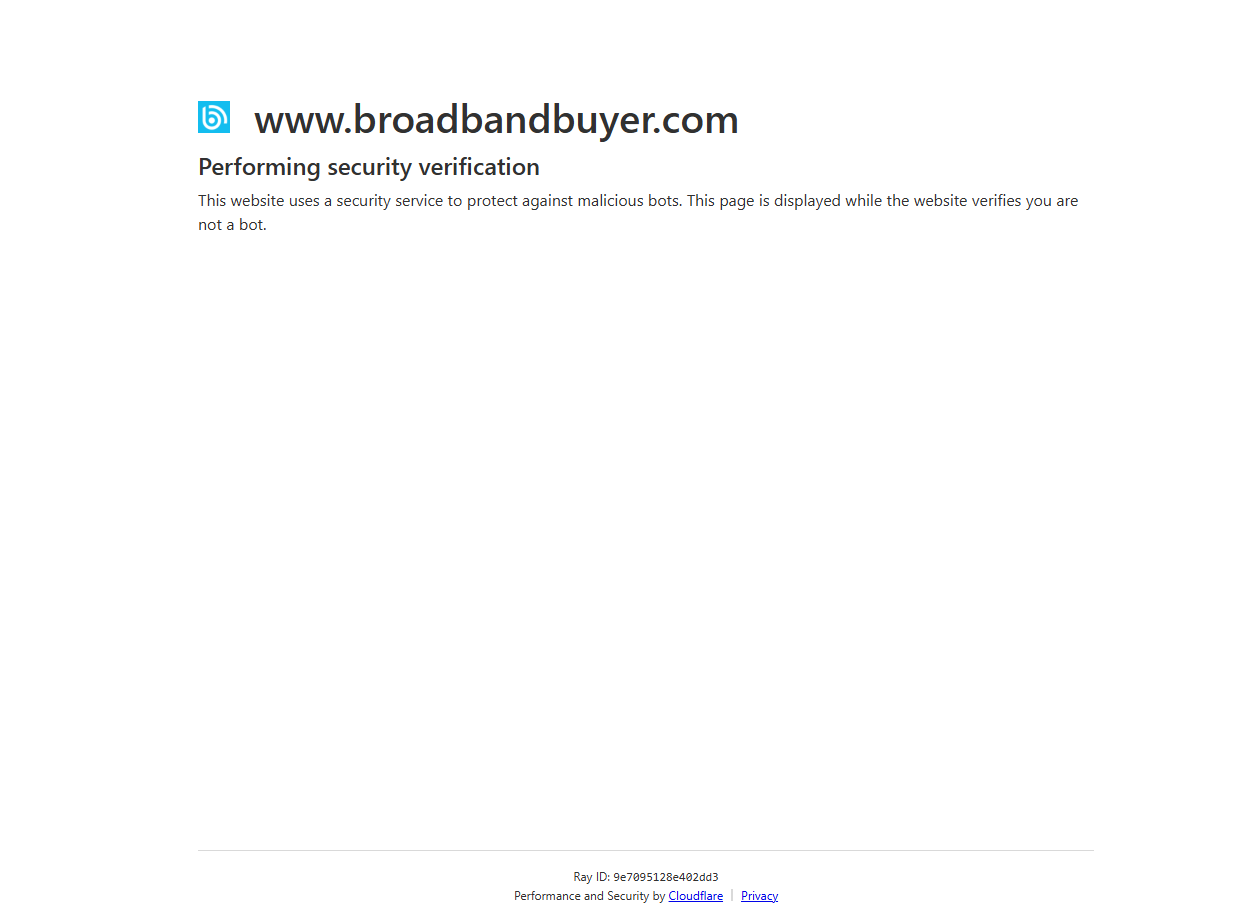
So Broadbandbuyer is using the Cloudflare bot challenges to prevent scraping slowing down their site.
They're not doing the wrong thing; up until recently that's what I'd have advised them to do if they were being scraped constantly without their consent.
But here's the thing, they're blocking the bots indiscriminately, and without an llms.txt, and the cloudflare-managed robots.txt file disallows all.
Cloudflare has controls for AI bot traffic now, a more targeted approach yields better results.
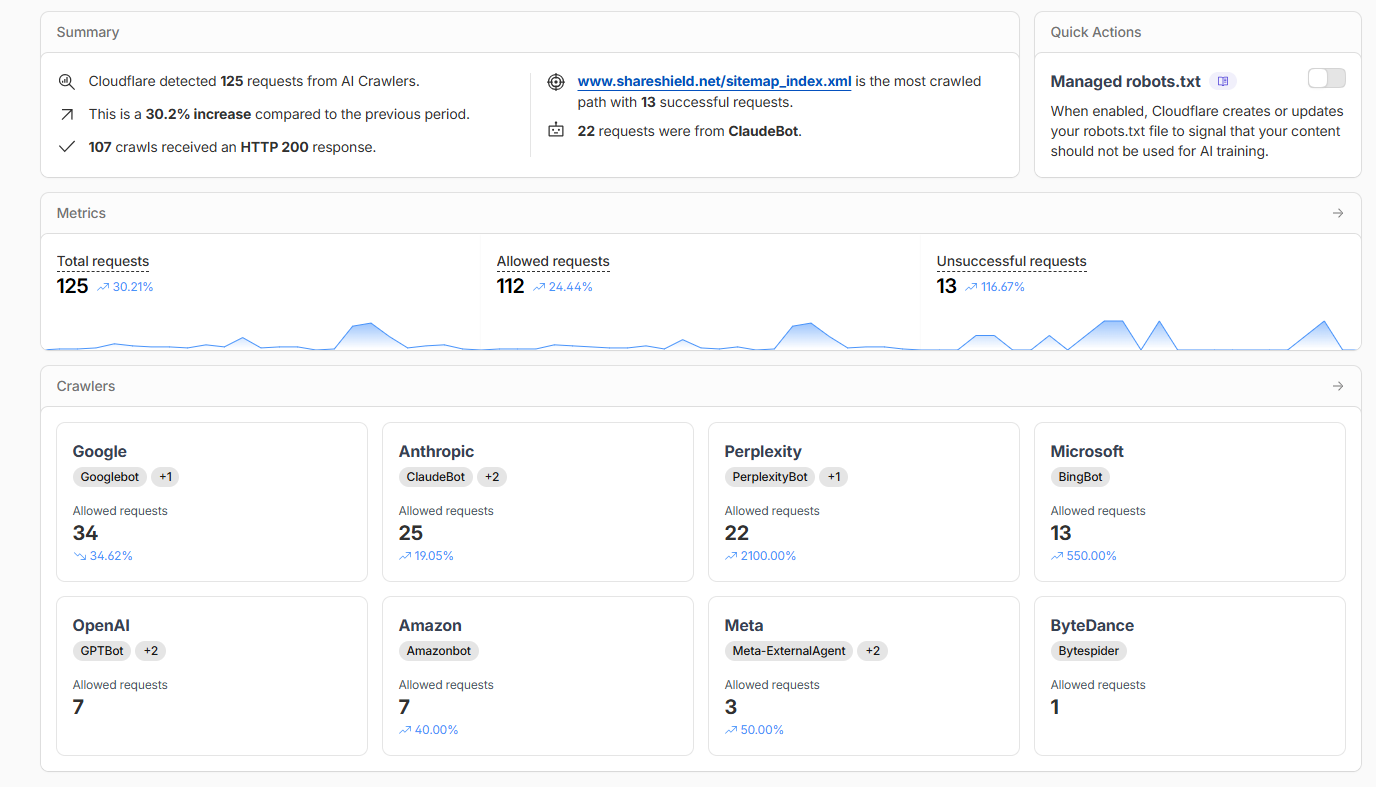
If broadbandbuyer allowed some of the main LLM agents, adopted the llms.txt file convention, and added JSON-LD structured data to the product pages, they'd rank much better in conversations with AI chatbots.
Conclusion
There's a justified defensiveness to blocking AI agents; we don't want our data scraped for training models that we didn't consent to, and we don't want OpenAI, Anthropic, Perplexity, etc. putting excess pressure on our site. Restrictive policies like broadbandbuyer's prevent that from happening.
At the same time, it allows their competitors like Direct Computers to dominate the emerging sales channel of LLMs and agentic AI.
It's not a theoretical "someday" hypothesis - this is happening now.
Check out Crawlmark to get a reading on your site completely for free, and if you want some help addressing the problems you find - you know where to find me.
Subscribe for more of this